Profil de document "brut" : "raw"
Avec ce profil de document aucun code complémentaire du serveur n'est sollicité: vous devez fournir votre fichier YML de description des données à extraire et vous traitez le résultat brut.
Exemple
Dans le cas d'un profil “brut” vous pouvez fournir ce que vous voulez, par exemple si vous voulez extraire des données du résultat du marathon de Paris 2003 (fichier https://www.athle.fr/pdf/resultat2003/MDP2003.pdf) … le document fait plus de 400 pages, pour notre exemple je vous propose de découper le PDF pour n'en garder que la première !
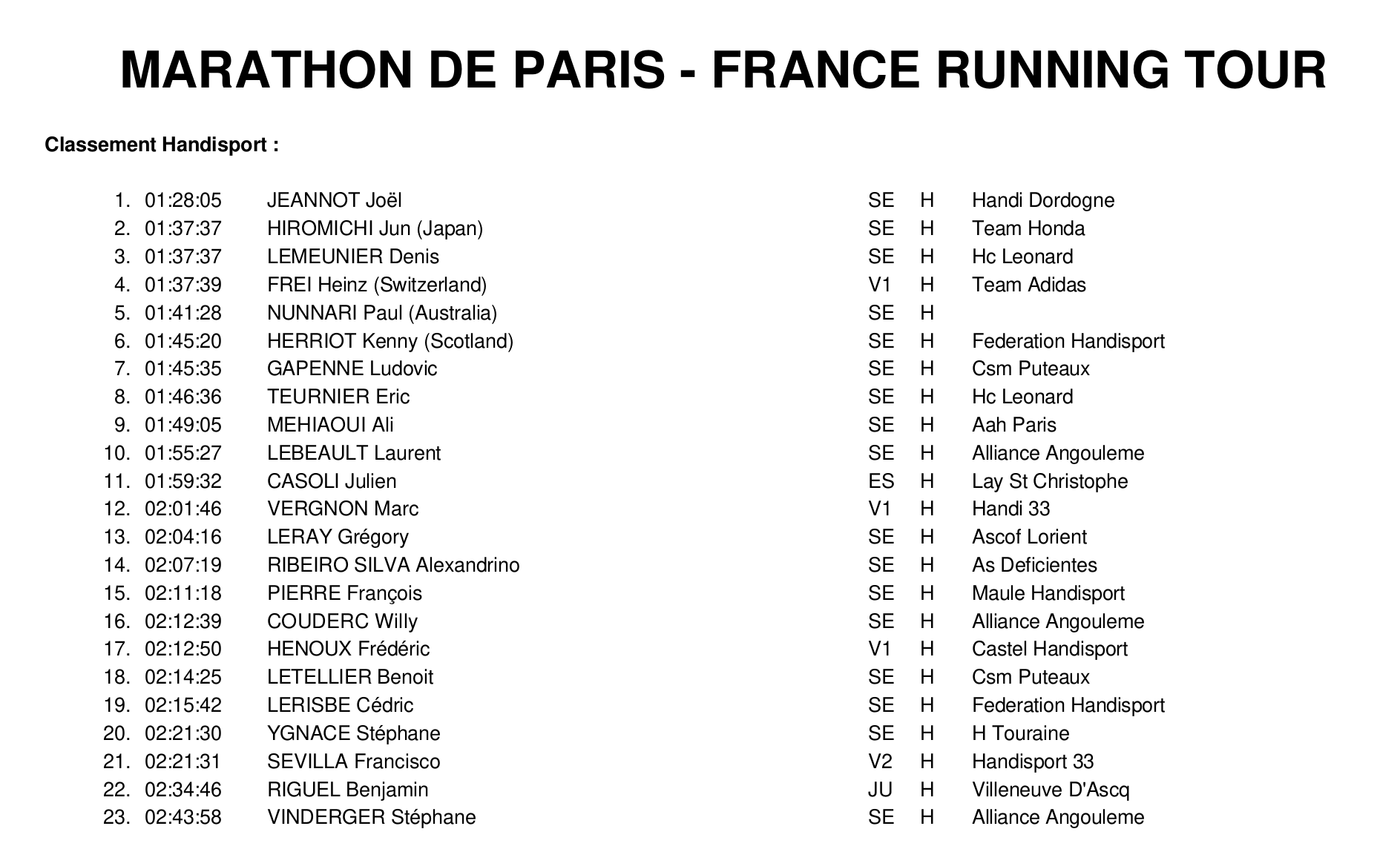
Création du fichier de masque d'extraction de données pour extraire les lignes du Classement Handisport:
issuer: marathon-paris.eric
fields:
title: MARATHON DE (\w+)\s
lines:
lines_start: Classement Handisport
lines_end: Classement Scratch
lines_line_tsv_before: (\d+)\.\s+(\d{2}:\d{2}:\d{2})\s+(.+)\s(\(\w+\))?\s+(\w+)\s+(\w)\s
lines_line_tsv_after: ^\s+\n$
lines_line_tsv_line1r: "(?<rang>\\d+)\\.\\s+(?<temps>\\d{2}:\\d{2}:\\d{2})\\s+(?<nom>.+)\\s(?<tag>\\w+)\\s+(?<sexe>\\w)\\s"
lines_line_tsv_line1f: rang,temps,nom,tag,sexe
extractor_engine: pdftotext
keywords:
- MARATHON
options:
decimal_separator: .
Lancement de l'extraction de données, résultat retourné par le serveur :
{
"error": "",
"json": {
"success": null,
"message": null,
"ocrID": "S3mYl6KKnJvx4IvbvQYrvOnSn9GDeRrcyIncn9ZE",
"jpeg": null,
"jpegBase64": null,
"pdfBase64": null,
"meta": {
"template_name": "S3mYl6KKnJvx4IvbvQYrvOnSn9GDeRrcyIncn9ZE.yml",
"title": "PARIS",
"decimal_separator": "",
"lines": [
{
"rang": "1",
"temps": "01:28:05",
"nom": "JEANNOT Jo\u00ebl ",
"tag": "SE",
"sexe": "H"
},
{
"rang": "2",
"temps": "01:37:37",
"nom": "HIROMICHI Jun (Japan) ",
"tag": "SE",
"sexe": "H"
},
.../...